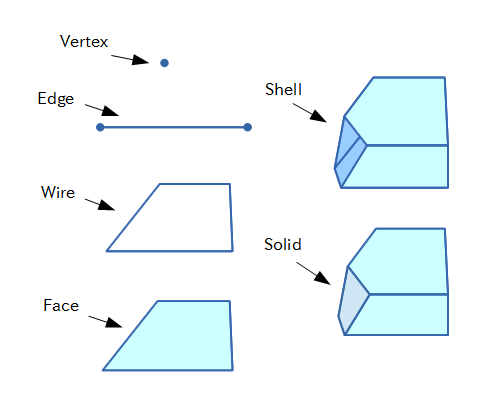
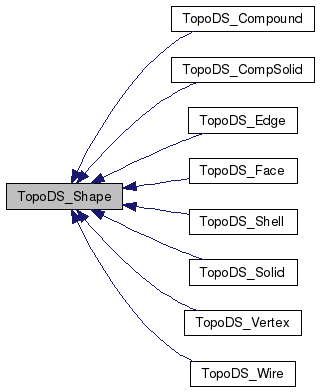
OpenCASCADE には、コマンド駆動型の効率的なデバッグ環境 Draw Test Harness というものが付属しています。 OpenCASCADE のコードを、単機能ごとに評価できるツールとして開発には外せないものであり、非常に有用なものです。快適なデバッグするのには、グラフィカルなユーザインタフェイスやイベント、コマンド実行の仕組み、簡単な繰りかえし処理や変数、数式の解釈など、かなり高次元なフレームワークを構築しないと、難しいものがあります。その「本質以外の部分」を担ってくれるのが Draw Test Harness です。
Draw Test Harness の簡単な説明
Draw Test Harness は Tcl 言語のインタプリタを内包しており、Tcl 言語のモジュールとして OpenCASCADE を利用された様々なコマンドを実行することができます。また、Viewer や簡単なマウス処理も提供されているので、対話的にコマンドを実行し、結果を三次元ビューで確認することができます。
Tcl 言語をご存知ない方にとっては、「今から新しい言語を覚えるのか…」と逃げ腰になる必要はありません。確かに Tcl はレトロな言語なのですが、インタプリタとしては使い古されており、あまり高度なことをしようとしない限り、充分に、クイックリーに動いてくれる環境です。基本的には、デバッグを自動化してくれるマクロという位置付けですので、バッチファイルやシェルスクリプトを書いたことがある方ならば、充分に使いこなせると思います。基本はコマンドの羅列です。
Draw Test Harness では GUI のメニューも提供されていますが、こちらは Tcl 言語の相棒といっても過言ではない GUI フレームワーク Tk で実装されています。こちらに関しては、Tk を用いて GUI を構築しようとしない限り、まったく知識は要りません。
Draw Test Harness を実行する
前項の手順で OpenCASCADE をインストールし、ros ディレクトリを指す環境変数 CASROOT が定義された状態を前提としています。X サーバが動いている端末または、Xを飛ばしたクライアント上から、次のコマンドをタイプします。
[bash] DRAWEXE [/bash]
GUIのメニューが表示され、端末には「Draw[n]>」というプロンプトが表示されたと思います。これが Tcl コンソールです。プロンプトに続けて、
[bash] pload ALL axo box b 10 10 10 fit [/bash]
とタイプしていくと、平行投影ビューにボックスが表示され、ビューにフィットすると思います。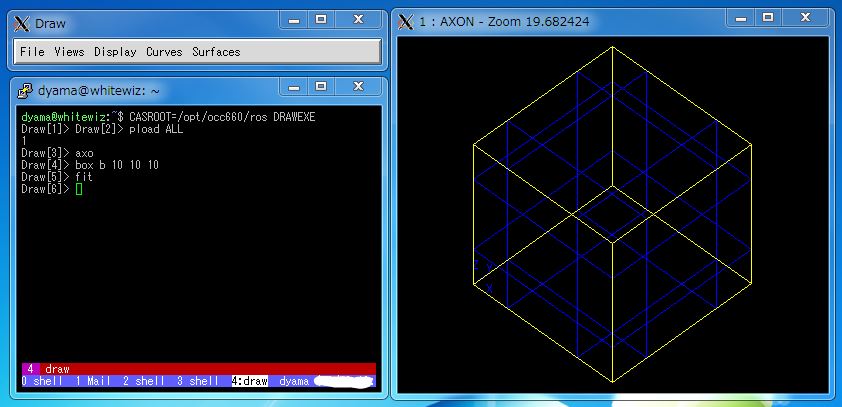
1行目の「pload ALL」は、モジュールファイルを全て読み込むコマンドです。このコマンドを最初に実行しておかないと、Tcl コンソールから OpenCASCADE モジュールをコールすることができません。(ちなみに、OpenCASCADE モジュールは、環境変数 CASROOT で定義された ros ディレクトリからパスを追っていき読み込んでいます。) 2行目の「axo」で平行投影ビューを表示して、3行目の「box b 10 10 10」で「(原点位置に)大きさ10,10,10のbというboxを作る」というコマンドです。最後の「fit」コマンドで、平行投影ビューいっぱいにboxの表示をフィットさせています。
最後に、「exit」とタイプすると Tcl コンソールが終了します。
このような具合で、コマンドを対話的にタイプしていって IGES を読み込んだり、オブジェクトの容積を出したりすることができるツールが Draw Test Harness です。 Tcl コンソール自体がインタプリタになっているので、上でタイプしたコマンドをテキストファイル box.tcl に保存しておき、
[bash] DRAWEXE < box.tcl [/bash]
することにより、一連の作業を自動的に処理させることもできます。 次の Tcl スクリプトは、ボックスと平面の交線(エッジを含むコンパウンド)を水平レベルごとに取得し、表示するサンプルです。
[perl]
!/usr/bin/env tclsh
pload ALL
ビューの作成
axo
ボックスの作成
box b 10 10 12 fit
ボックスを傾ける
trotate b 0 0 0 1 0 0 14 trotate b 0 0 0 0 1 0 -21 fit
水平面で交線を求める
for {set i 1} {$i <= 14} {incr i} { plane p$i 0 0 $i 0 0 1 psection c$i b p$i unset p$i } [/perl]
簡単な制御構文を用いています。私自信、Tcl 言語はそれほど書いたことあるわけではないのですが、以前のブログ記事を見てみるとこんなモノも書いていたようです。全然覚えてないな・・・。
Windows 環境では、CASROOT ディレクトリ(ros)直下にある draw.bat をダブルクリックすると、Tcl コンソールが開きます。
Draw Test Harness を使った応用
Draw Test Harness には、OpenCASCADE モジュールとして提供されているコマンドが数百種類もあります。ここでは、一つ一つに関しての説明は省きますが、これらのコマンドを組み合わせることで、ちょっとした非対話的な CAD ないし、三次元データコンバータくらいなら書けてしまいます。また、DRAWEXE の標準入出力をつないだアプリケーションを書けば、コマンド駆動型、かつしっかりとしたGUIを積んだアプリケーションを書けないことはありません。ちょっとした IGES ファイルの形状のチェックや、形状を反転・拡大縮小したい場合などにも力を発揮します。
また、提供されているコマンドの実装はソースコードレベルで公開されていますので、例えば、三次元オブジェクトの重心位置を取得するコードを書きたい場合、Draw コマンド vprops の実装を調べれば良いわけです。Draw インタプリタ内で「getsourcefile vprops」とタイプすると、ソースコードのファイル名を教えてくれます。そのファイル名を基に $CASROOT/ros/src から目的のソースコードを探し出すことができます。Draw コマンドは、基本的には単機能ごとに機能を提供しているものなので、Draw コマンドの実装方法が「最強のサンプル集」となることでしょう。
さらに、Draw Test Harness では、既存のコマンドに加え、ユーザが C++ を用いてコーディングした OpenCASCADE のコードも簡単に呼び出すことができます。OpenCASCADE を使う、つまり C++ で OpenCASCADE を使う場合、Draw Test Harness は最強のデバッグビューアとなるのです。
次回は、Draw Test Harness に自分で書いた OpenCASCADE コードを独自のコマンドとして登録し、実行してみます。
 本日のまとめ
本日のまとめ
- Draw Test Harness は、コマンド駆動型の強力な OpenCASCADE インタプリタ。
- 面倒な GUI 周りが最初から準備されているので、三次元幾何演算のトライアンドエラー、プレビューがかんたんにできる。
- 対話的に利用するもよし、数百種類あるコマンドを組み合わせてバッチ処理をさせてもよし。
- それぞれのコマンドは、source commandname によって C++ のソースコードを参照できる。