Twitter の常駐監視型メディアダウンローダー berryjack の Windows 移植版を作成しました。品質無保証の人柱版として公開します。 概要 監視対象となるアカウントを定期的に巡回して、メディアファイル(…
タグ: シェルスクリプト
ツイキャス録画スクリプト
リアルタイム動画配信サービス「ツイキャス」の録画をしてくれるシェルスクリプトを書いてみました。…と言っても、ffmpeg の入力ソースに食わせるだけですので、スクリプトというよりは例によって自分の覚え書きのようなものにな…
MD5ハッシュ値をURLセーフな文字列に変換
大量に保存した画像ファイルなどの重複潰しも兼ねて、ファイル名を MD5 ハッシュ値にリネームして保存しています。 dyama/hashmv · GitHub まったく同一のファイルであれば、ハッシュ値が同一になりますので…
Twitterの画像を一括ダウンロードするシェルスクリプト「berryjack」を書いた。
以下、スクリプトの解説が中心です。Windows で手軽に使いたい方は berryjack/win32 をダウンロードしてください。 数年前、知人より「Twitterの特定アカウントで公開されている画像ファイルを一括ダウ…
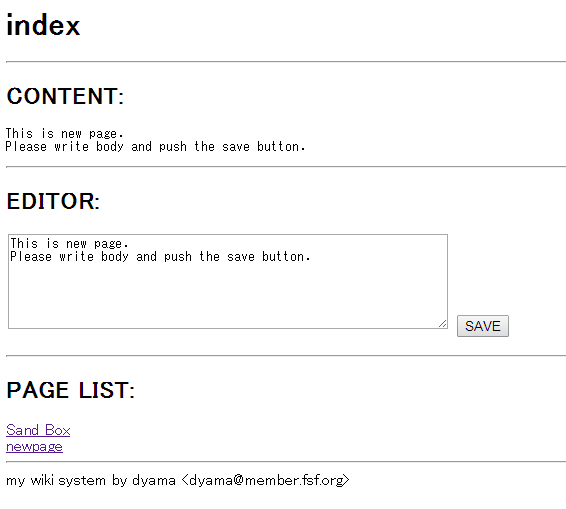
シェルスクリプトによる簡易Wikiシステム
以前、PQI Air Card でも動く簡易 Wiki を書いてみました。PQI Air Card 自体、標準で Perl が動いていますし実用性はあんまりないですが、シェルスクリプトベースでも簡単に出来てしまいます。 …
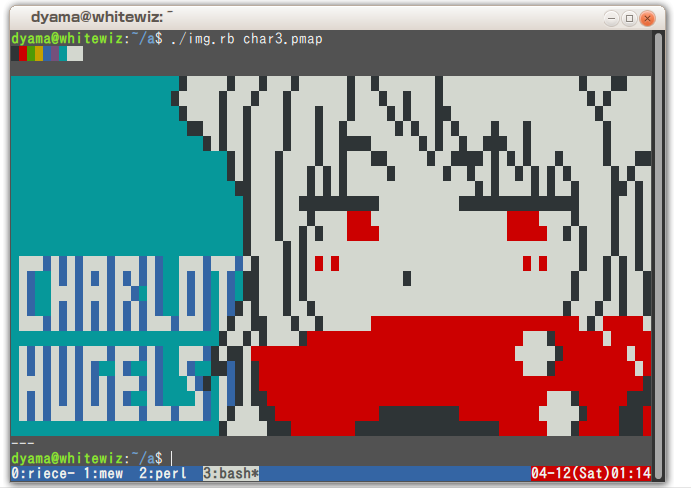
ANSI エスケープシーケンスについて
端末の色やカーソル制御を行うには、curses を利用するのが一般的ですが、ライブラリを利用しなくとも、シェル経由である決まりのエスケープシーケンス文字列を端末に投げることにより、色やカーソル制御を行うことができます。 …
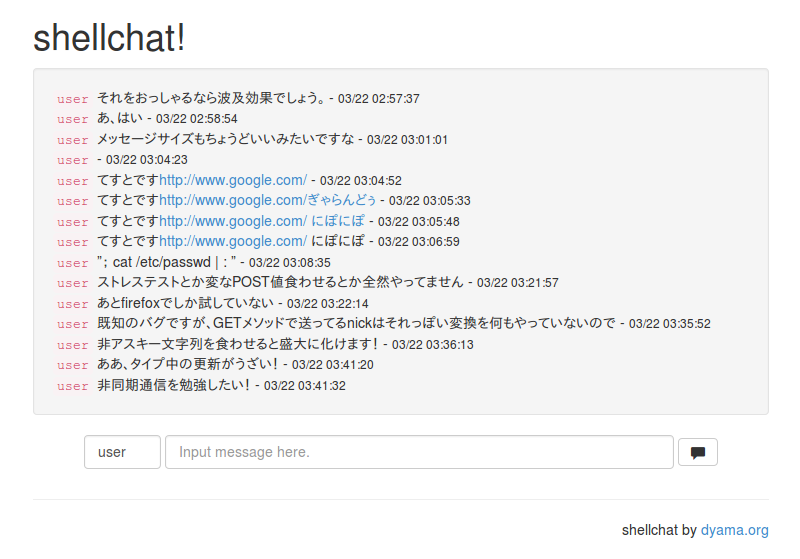
シェルスクリプトでCGIチャットを書いてみました。
CGIは、標準入出力と環境変数を用いて動的コンテンツを生成する仕組みなので、これらを扱うことができるプログラムだったら記述言語は問いません。CGIと言えば「CGI/Perl」の組み合わせだけが突出して有名ですが、CGI/…
音声合成エンジン Open JTalk について
動画の生放送サイトを見ていると、リアルタイムに視聴者から来るコメントを合成音声によって読み上げている人が増えているようで、合成音声のジャンルも賑わってきたようです。ボーカロイドの初音ミクが登場するよりも前、AquesTa…
自炊ZIPをスマホや電子ブックリーダー向けに最適化する
去る2月、楽天の Kobo を中古購入しました。投げ売り価格の2500円でした。私は風呂でよく本を読むので、浴槽に落としてもそんなに凹まない安価な端末を探していました。期待をまるでしていない、という意味では Kobo は…
tumblrの画像を一括ダウンロードするスクリプト
tumblrの画像を一括ダウンロードするbash向けシェルスクリプトを書いてみました。 あまり効率的ではないですが、投稿を1ページずつ取得して、含まれる画像を抜き出しています。また、ダウンロードが完了したらZIPファイル…