
こんばんは、サポート切れの LMDE をいつまでもうだうだと使っている dyama です。OS も古ければ、ハードウェアも古くなってしまい、CUDA 系のライブラリを入れるのもひと苦労な僕です。
さて、友人の920さんより「Stable Diffusion の環境構築をしよう」と誘われていて、今更ながら下調べ&ハンズオンで試してみていました。
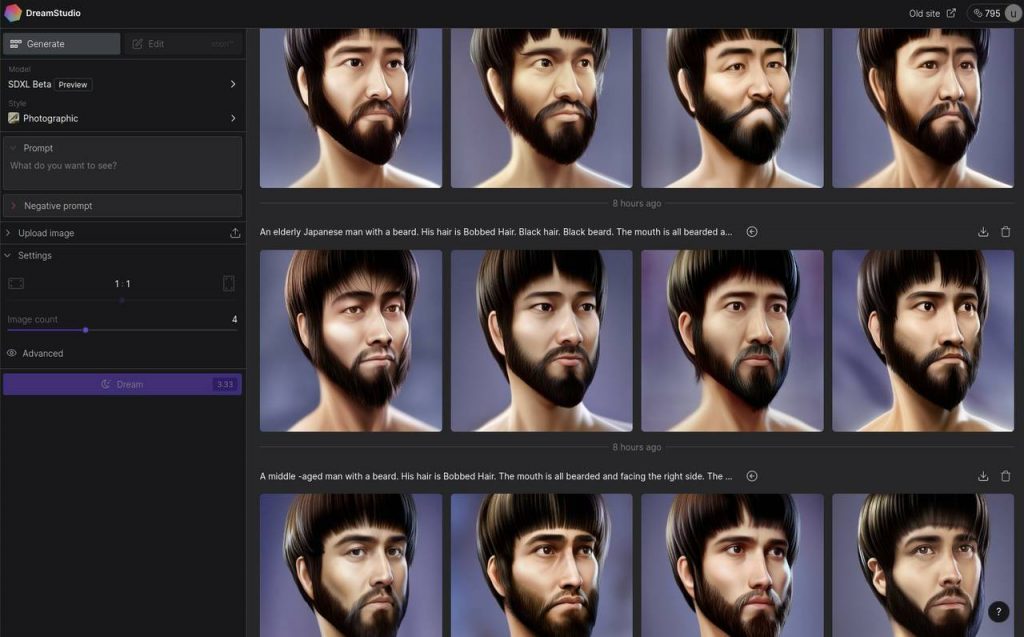
フロントエンドサービス Dream Studio
手元の環境要らずの Stable Diffusion フロントエンドサービスと言えば、まず思いついたのが Dream Studio です。実際に使ったことがなかったので、いろいろと試してみるとすぐに無料枠の250クレジットを使い果たしてしまいました。追加で10ドル(約1,310円)を支払い、1,000クレジットを購入して触りました。
ちょうど、Stable Diffusion XL のベータ版が公開された日だったので、選択できる学習モデルは
- Stable Diffusion v1.5
- Stable Diffusion v2.1
- Stable Diffusion v2.1-768
- SDXL Beta [Preview]
の4種類。DreamStudio のクレジット消費は、1プロンプトに対する生成画像数、解像度、使用するモデル、ステップ数によって変動するようです。現状は SD v2.1-768 が一番お高い模様。名前的に 768px サイズでの学習モデルっぽいですね。

上記は「Japanese room, tatami, shouji」というプロンプトを与えてみた例。割と高速に結果が返ってきます。ブログや Youtube で使用する背景イメージ写真くらいの漠然とした画像であれば、本当にこれで充分になってしまいましたね。フリー素材の写真を探さなくても良い時代です。
また、ベースとなる画像を指定することも可能ですので、ラフスケッチをアップロードしたら仕上げてくれる感じにもなります。


Stable Diffusion のプロンプトは、俗に「呪文」と呼ばれているらしく、Google 検索するといろいろなまとめサイトや呪文生成器(ジェネレーター)が出てきました。去年の夏に誕生して、まだ1年経っていないのにこの界隈は毎日のように進化を続けていて情報がたくさんですねー。
学習モデル ChilloutMix
Twitter の AI アート界隈のタイムラインを見ていると、2次元イラスト風の作例のほか、実写のような画像をよく目にします。これらの多くは、Stable Diffusion の ChilloutMix というモデルを使って生成された画像のようです。
日本人の TASUKU2023 さんが「海外の学習モデルだと日本人らしく、特に可愛い人物像が生成できない」という事で作り、公開されているものらしいです。Youtube に開発の経緯などのインタビューがあります。
動画の中で印象だったのは
『beautiful eyes』というプロンプトを入れると、目が青くなり白人風になるから入れない方がいい
と言っていた点。
欧米で作られた学習モデルはどうしても白人中心社会の価値観によってラベリングされてしまうので、文化によって主観や好みが大きく異なるジャンルの難しさがあることを知りました。そのため、日本人の観点で生成された学習モデルということに意味がありそうです。
Stable Diffusion Web UI on Google Colab
Stable Diffusion が Google Colaboratory (以下、Colab) で手元環境なしで構築&実行できるようです。Colab とは Google が提供する Jupyter notebook の PaaS で、CPU、GPU とファイルシステムのリソースを借りてブラウザから Python コードを実行できる環境です。
まず、Colab の画面を開き、新規の notebook を作成します。「編集」メニューの「ノートブックの設定」を開き、ハードウェア アクセラレータを「GPU」に設定します。
※Colab Pro (有償プラン) に契約しなくても GPU を使用することができますが、使いすぎると制限がかかるようです。
スクリプトエディターに戻り、次のように入力して実行しました。(参考記事)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui
!wget https://civitai.com/api/download/models/11745 -O /content/stable-diffusion-webui/models/Stable-diffusion/Chilloutmix-Ni-pruned-fp32-fix.safetensors
!python launch.py --share --xformers --enable-insecure-extension-accessStable Diffusion Web UI を clone して、その中に ChilloutMix のモデルデータをダウンロードし、 Web UI を実行してます。
すると、次のエラーメッセージが出ました。
RuntimeError: Detected that PyTorch and torchvision were compiled with different CUDA versions. PyTorch has CUDA Version=11.7 and torchvision has CUDA Version=11.8. Please reinstall the torchvision that matches your PyTorch install.試した時には、数日前に CUDA の使用バージョンが変わっていたようでバージョンを合わせてあげる必要がありました。
launch.py を実行する前に、pip で明示的にバージョンを合わせて入れ直してあげます。
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd /content/stable-diffusion-webui
!wget https://civitai.com/api/download/models/11745 -O /content/stable-diffusion-webui/models/Stable-diffusion/Chilloutmix-Ni-pruned-fp32-fix.safetensors
%pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchtext==0.14.1 torchaudio==0.13.1 torchdata==0.5.1 --extra-index-url https://download.pytorch.org/whl/cu117
!python launch.py --share --xformers --enable-insecure-extension-accessこれで、表示されたリンクを開くと Web UI にアクセス可能になりました。
Stable Diffusion Web UI の使い方については、様々なページで解説されているのでそちらを参照してください。
Stable Diffusion で ChilloutMix を使ってみた結果
まずは作例から少し掲載しておきます。プロンプトやパラメーターの与え方にも大きく左右されますが、割とそれらしい画像を生成することができています。

でも、ほとんど加工せずにポスターなどの素材に使えそう。


マスクの柄はさておき、違和感なく表現されている。
ふと良い歳のオッサンが美少女写真をいじくり回していることに気付きました。とても複雑な気分になりますね/(^q^)\
まぁ、対象がリアルだからこそ感じられる感覚とも言えます。そこで、写真の奥のリアリティを求めなくても見ていられる「非日常」的なイメージを作ってみようと方針転換しました。


まとめ
「AI 絵師」という言葉が台頭してきて少し経ちますが、あまり詳しくない時は「プロンプトを投げれば、あとはAIにお任せ」みたいな印象が多少なりともありました。
実際に触ってみると、そうとも言えませんね。特に細かなところまで指定し始めたら、思ったような江が出てくるまでに多くの時間と知識が必要なようです。
気付いた点をいくつか挙げておきます。
- フォトリアルで高品質な写真っぽい画像を生成するため、それなりのプロンプトが重要。
- 畳み込み計算のステップ数は、20〜30程度。10前後だと足りなくて破綻しがち。
- Stable Diffusion の学習モデルは 512 px サイズが基本。それを意識して生成後に高解像度化する手法が一般的。
- 生成時解像度とプロンプトの組み合わせをミスると、簡単にクリーチャーが出てくる。
- プロンプトの指定の仕方に頭を使う。英語力も必要で、かつ Stable Diffusuion に理解しやすい表現が必須。
- 特にポージングは ContorolNet のようなものを組み合わせないと難しい。テキストプロンプトでの指定は現実的ではなさそう。
- 今後は ChilloutMix のライセンスまわりを綺麗に整理した Generic 商用可能版を使うといいみたい。
- Stable Diffusion で Depth 推定する技術は存在している。また SD 開発元が Blender 向けの環境も提供している。
- ここ数日で、ChilloutMix で生成した画像を疑似3D(?)っぽく動かして ChatGPT と繋げて会話するデモを見かけた。
- GPT で SD 用プロンプトを吐かせる手法があるらしい。
- 画像生成や AI を駆使した VTuber も既にいるらしい。
ChilloutMix の作者さんのインタビューで述べられていたことばかりですね。やってみて実感しました。そしてとにかくこの界隈は週に何個もニュースが出てくる勢いですので、一夜漬けで追いかけるのは大変でした。少し追いつけたかなぁ。
何に活用できるかについては、今のところ ChilloutMix を使った Stable Diffusion 環境は「可愛い画像がたくさん作れる」以上でも以下でもなく、僕の力量や活動では生かせる自信はありません。
社会として見ると、AI からのアプローチでバーチャルヒューマンの見た目の世界が広がっていく瞬間を垣間見た気になりました。3D CG の Saya がスゴいリアルだなって思ったのがつい数年前だったのに、自動生成が実写と見分けが付けづらい時代になってます…早い。